Migrate From Any Database Type
ApertureDB is a graph-vector database purpose-built for multimodal AI. It is the unifying backend for the entire AI/ML pipeline. Only painful DIYs are the full alternative today:
We have summarized AI use cases that we solve for our customers today. Since, the challenges we address are prominent in the context of Multimodal AI use cases, we use the data layer requirements in such cases to guide our comparisons below.
Comparison with Traditional Databases
Today’s databases need a lot of additional help to achieve what ApertureDB does. We have already discussed migrating from a relational database in great detail and summarize an example in the table below. In this table, we also introduce some other popular NoSQL database types for a more complete picture to help compare ApertureDB with various databaes.
| Requirements | MongoDB (document db) | Neo4j (graph db) | SQL (relational db) | ApertureDB |
|---|---|---|---|---|
| Store and process unstructured types like images, videos | Store binary files up to 100M but lose "image" or “video” recognition. No native processing or visualizing | No storage or recognition for processing of unstructured types. Needs a DIY layer as shown earlier for anything complex like processing or visualizing | No storage or recognition for processing of unstructured types. Needs a DIY layer as shown earlier for anything complex | Natively recognizes images, videos and supports pre-processing e.g. intervals or frame rate changes. Also supports other types as blobs |
| Store and search regions of interest (annotations, clips) | JSON can be directly stored and search but harder to connect with unstructured types | Annotations could be modeled and relationships established to image or video nodes but no pixel retrieval in regions of interest or IoU | Annotations could be modeled though schema is less flexible and foreign keys established to images or videos but no pixel retrieval in regions of interest or IoU | Natively supports regions of interest and their relations to image / video objects. Easy to search, fetch RoI pixels, IoU |
| Store and search metadata | JSON storage and search | Property graph model for complex searches | Relational model making connected data searches harder to write and usually longer to execute and schema is harder to evolve | Property graph model for complex searches |
| AI/ML Support | Not designed for it but need complex, one-off DIY scripts | Has some support with Neo4j data science but its more for numerical quantities | Support varies but for building video training, connecting to annotations, visualizing video stuff, need lots of DIY | AI/ML framework connector, annotation connector, batching, and other AI tools support |
| Vector search | Not designed for it but indexes are being overlayed | Has some graph vector search support now in the DS suite | Not designed for it but indexes are being overlayed | In-depth support |
Key value and time series databases provide a smaller subset of capabilities compared to the chosen categories of databases.
Another significant difference, just from a database perspective, is our ability to offer data consistency at the level of queries that involve both, metadata and data, something that data engineers have to manually enforce in the DIY systems they are forced to build today.
Comparison with Vector Databases
We also compare ApertureDB to a couple of the popular vector databases. There are some common features across all three
- Variety of exact / approximate search engines with different distance metrics
- Embeddings from a variety of multimodal data for similarity searches
- Support for CRUD operations, at least over vectors and attached metadata attributes
However, since we take a holistic approach to data management, what we offer goes beyond just vector databases (ApertureDB is an enterprise ready vector db + more). The table below answers the question around how we are different:
| Requirements | Pinecone | Milvus, etc. | ApertureDB |
|---|---|---|---|
| Support for rich metadata for rich filters and access to corresponding multimodal data | Simple attributes attached to vector but have to correlate ID with source data outside of Pinecone | Columns of SQL-like attributes attached to vector but have to correlate ID with source data outside of DB |
|
| Access model | Fully SaaS | Open source, cloud hosted, installs in VPC | Community edition, cloud hosted, installs in VPC |
| ACID transaction support | Only over supported vector data | Only over supported vector data | ACID compliant across multimodal data including embeddings and graph metadata |
| Performance | Data and use case dependent | Data and use case dependent | 2-4X higher better throughput for customer use case. Scales to larger dimensions |
| Seamless integration with overall ML / analytics pipelines | Just built for vector search, now Langchain-style integrations | Just built for vector search, now Langchain-style integrations | Integrates with:
|
Comparison Across AI Pipelines
AI teams today expect their data layer to let them manage different modalities of data, prepare data easily for AI/ML workloads, be easy for dataset management, manage annotations, track model information, and let them search and visualize data using multimodal searches.
Sadly their current choice to achieve each of those requirements is a manually integrated solution (DIY) where they have to bring together cloud stores, databases, labels in various formats, finicky (vision) processing libraries, and vector databases, in order to transfer multimodal data input to meaningful AI or analytics output. Such DIY systems consume too much time from AI teams (sometimes 6-9 months), are long to install, bad for debugging, and painful to maintain. AI teams are very skilled, hard to hire or retain, and the last thing we want is having them maintain infra code.
The right Database needs to not only understand the complexity of multimodal data management but also understand AI requirements to make it easy for AI teams to adopt and deploy in production. That’s what we have built with ApertureDB.
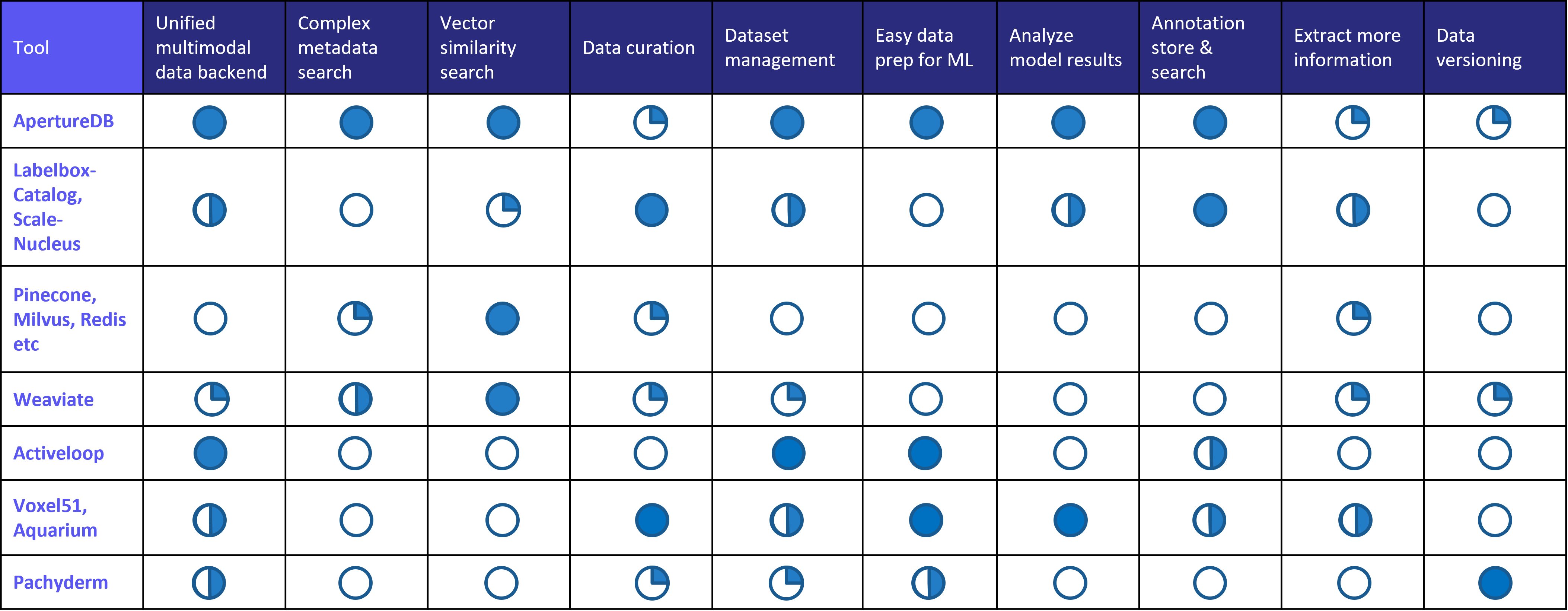
Given our work lies at the intersection of database and machine learning, we also have a comparison chart for ML tools.
For an example of how to manage multimodal data in ApertureDB, checkout our Cookbook examples.