What is ApertureDB?
ApertureDB is a graph-vector database purpose-built for multimodal data. ApertureDB stores and manages images, videos, documents, feature vectors (embeddings), and associated metadata like annotations. It natively supports complex searching, preprocessing, and display of media objects.
ApertureDB Core Architecture
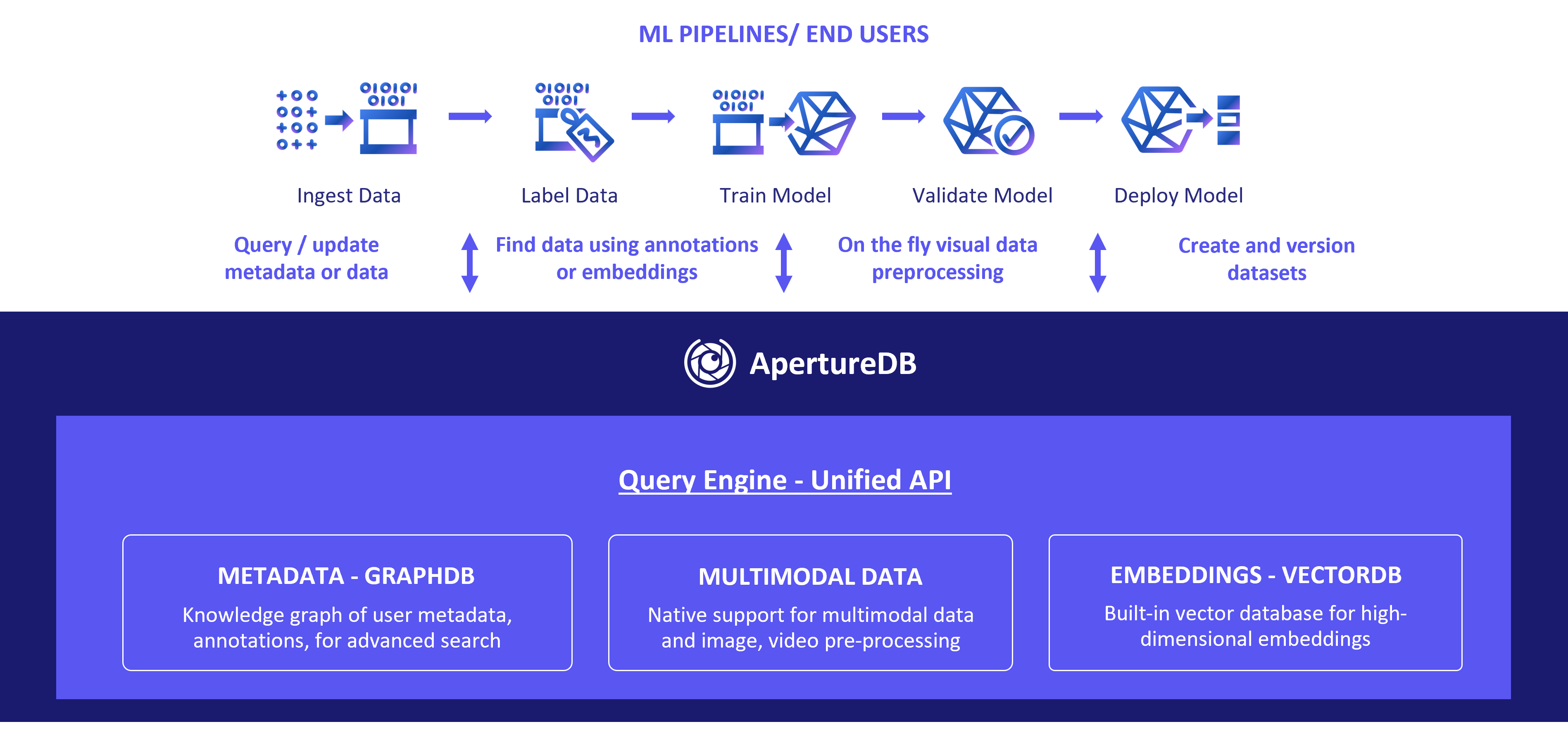
The core architectural components of ApertureDB are:
- Vector Database: Feature vectors, descriptors or embeddings extracted from images, text, documents, or frames, make it possible to find objects by similarity. ApertureDB offers similarity search over n-dimensional feature vectors or embeddings building on top of Facebook's FAISS library.
- Graph Database: Metadata is key for many applications. ApertureDB uses an in-memory graph database to store application metadata allowing users to create a knowledge graph. Multimodal data, embeddings, and application information are represented within this metadata. This helps to capture internal relationships between metadata and data, as well as to enable complex searches based on this metadata. In order to target ML applications, ApertureDB also supports bounding boxes and other regions of interest for labeling or annotation based searches, as part of the metadata.
- Multimodal Data Management: ApertureDB supports management of multimodal data types like text, documents, images, audio, and videos as native entities. Given the range of usages for this data, and our past experience with computer vision data, we provide necessary preprocessing operations like zoom, crop, sampling, and creating thumbnails as you access the data via internally-linked libraries like OpenCV and ffmpeg. You can store other modalities of data like documents, audio, text as blobs, but without specific operations to pre-process them at this time. ApertureDB can store and access the data from disks mapped to the ApertureDB server or cloud object stores.
- Unified Query Interface: An important design goal for ApertureDB was to not have its users deal with multiple systems. Therefore, ApertureDB uses a query engine or an orchestrator to redirect user queries to the right components internally, and collects the results to return a coherent response to the user. It exposes a unified JSON-based native query language to the ML pipelines and end users.
These pipelines or users can execute queries that can add, modify, and search multimodal data and metadata, annotations or feature vectors, perform on-the-fly visual preprocessing, and do other AI/ML tasks like the creation of datasets, generating responses, RAG, finetuning of models, and so on.
Besides the core components, in order to scale horizontally for larger workloads as well as for high availability, ApertureDB is enterprise-ready and distributed which implies quite a few more components. You can find more details here.
Key Features
ApertureDB is unique when compared with other databases and infrastructure tools because:
- Multimodal ACID transactions: ApertureDB implements ACID transactions for the queries spanning the different data types thus offering relevant database guarantees at the level of these complex objects.
- Cloud-agnostic: ApertureDB is designed to be cloud-agnostic. The data management layer can read and write data from and to the various cloud object stores (e.g. S3, GCS) or from POSIX-compliant file systems.
- Data augmentation: It natively supports images in different formats and videos with multiple video encodings and containers, together with efficient frame-level access. Images and videos can be augmented or modified on-the-fly, avoiding the need to create copies in predetermined formats that can cause data bloat.
- Multimodal queries: The graph database supports metadata representing different modalities of data as shown in the example schema here. ApertureDB can be used to index embeddings using different indexing methods. This enables vector search and classification to be performed at runtime with a combination of indexes and distance metrics. It supports additional metadata constraints on top of the K near neighbor searches.
- Annotations, labels, captions: Any number of regions of interest with labels and in various shapes can be associated with images or frames with operations that allow extracting just the pixel data. This can reduce the amount of data transmitted over the network. These are associated with the rest of the metadata to continue building the knowledge graph of an application. Similarly, you can indicate video clips and frames in metadata and completely avoid duplicating data. You can associate captions or other label text with any other modality of data managed in ApertureDB.
- Multimodal visualization: You can navigate graphically and debug your visual datasets using ApertureDB UI.
- AI/ML Integrations: ApertureDB can support large scale AI/ML training and inference operations through our batch data access API representing the keyword and/or feature based searches in users' existing AI/ML workflows. ApertureDB also supports ETL and Gen AI use cases with various models and integrates with various Gen AI frameworks as discussed with examples in our Integrations section.